


 您當前的位置 :
您當前的位置 : 





科技巨頭Meta回應了對公司最新開源AI(人工智慧)模型Llama 4的質疑,否認該模型在訓練集中作弊“刷分”。
當地時間4月7日,Meta的生成式AI負責人Ahmad Al-Dahle在社交平臺上發佈了一篇長文,回應了對於Llama 4的質疑。Ahmad表示,由於Llama 4剛開發完就迅速發佈,所以模型“在不同服務中表現出了參差不齊的品質”,公司會儘快修復漏洞。同時,Ahmad否認了Llama 4在訓練集中作弊“刷分”的說法。
兩天前,4月5日,Meta推出了旗下最受歡迎的模型系列Llama的最新一代模型,包括較小模型Scout和標準模型Maverick這兩個版本。此外,Meta還展示了被稱為“迄今最強大、最智能”的模型Llama 4 Behemoth的預覽。
據介紹,Llama 4模型是Llama系列模型中首批採用混合專家(MoE)架構的模型,在多模態性能上表現出眾。其中,最先進的Llama 4 Behemoth的總參數高達2萬億,擔當了其他模型的“老師”;Scout和Maverick的活躍參數量為170億,Scout主要面向文檔摘要與大型代碼庫推理任務,Maverick則專注於多模態能力。
 Meta一次性介紹三款Llama 4模型。來源:Meta
Meta一次性介紹三款Llama 4模型。來源:Meta
作為原生多模態模型,Llama 4採用了早期融合(Early Fusion)的技術,通過使用大量無標籤文本、圖片和視頻數據一起來預訓練模型,將文本和視覺token無縫整合到統一的模型框架中。此外,Llama 4在長文本能力上也取得了突破,Scout模型支持高達1000萬token的上下文窗口,Maverick模型則支持100萬token的上下文窗口。
不過,Llama 4一經發佈就遭到了質疑。Meta的發佈介面顯示,在評估代碼能力的LiveCodeBench測試集和大模型競技場(Chatbot Arena)中,Scout和Maverick都表現得很不錯。但許多開發者發現,這些模型在小型基準測試中的表現令人失望。
例如,有網友指出,在一項讓模型完成225項編程任務的名為aider polyglot的基準測試中,Llama 4 Maverick只取得了16%的成績,遠低於Gemini 2.5 Pro、Claude 3.7 Sonnet和DeepSeek -V3等規模相近的舊模型。
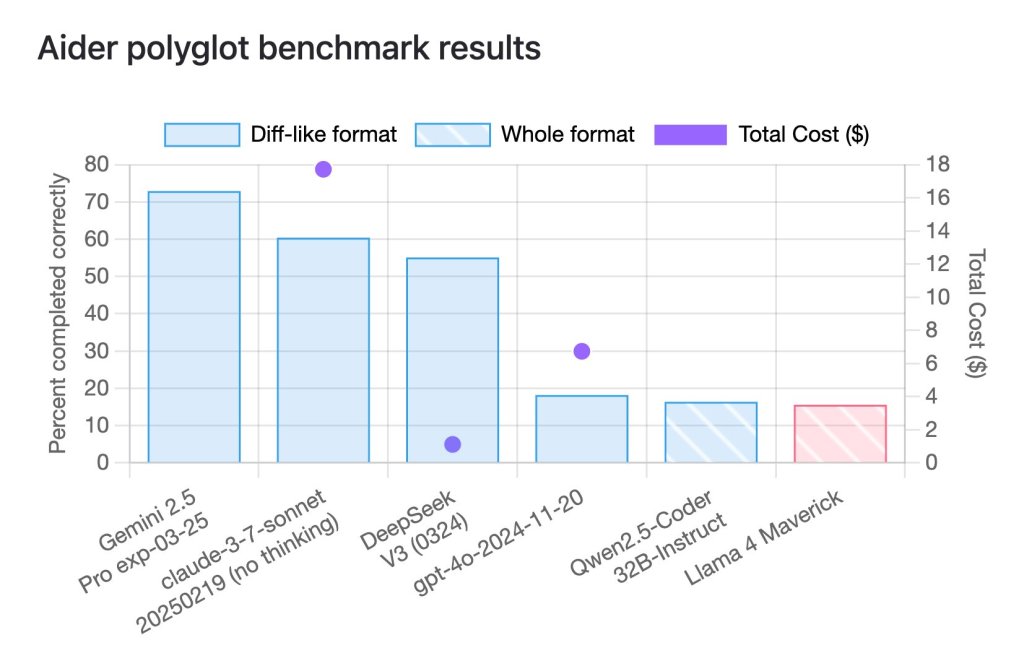
Llama 4 Maverick在小型測試集上成績不如人意。來源:X平臺
AI工程師和技術作家Andriy Burkov則在社交平臺X上指出,Meta稱Llama 4 Scout擁有1000萬token的上下文窗口,而這其實是一個“偽命題”:“實際上,不會有任何模型針對超過256000個token的提示詞進行訓練。如果你向它發送這麼多token,在大多數時候只會得到低質量的輸出。”
對於Llama 4令人失望的表現,一些開發者開始懷疑,為了在測試集中取得更好的成績,Meta為這些測試集製作了“特供版”Llama 4。例如,前Meta研究員、現任AI2(艾倫人工智慧研究所)的高級研究員Nathan Lambert在經過比較測試後指出,在大模型競技場中取得成績的Llama 4 Maverick與該公司公開發佈的版本不同,前者是“在對話性上進行了優化”的版本。
此外,就在Llama 4發佈的前幾天,在Meta工作了8年的AI研究主管Joelle Pineau宣佈離職。聯繫到Llama 4的表現,更加深了網友對於Llama 4“暗箱操作”的質疑。而在國內社交平臺上,也有自稱為Meta內部員工的網友稱“Llama 4的訓練存在嚴重問題”,自己已經向公司提交了離職申請,AI研究主管的離任也是出於同種原因。
這位網友表示:“經過反復訓練,其實內部模型的表現依然未能達到開源SOTA(指在研究任務中表現最好的模型),甚至與之相差甚遠。公司領導層建議將各個benchmark(基準)的測試集混合在post-training(後訓練)過程中,目的是希望能夠在各項指標上交差,拿出一個‘看起來可以’的結果。”
可以肯定的是,Llama 4的初始發佈並沒有給AI社區帶來巨大的積極反響。目前,面對進步迅速的中國AI模型,Meta急於穩住Llama系列在開源領域的領先地位。今年2月,阿裏通義千問(Qwen)系列模型的下載量已經達到了1.8億,累計衍生模型總數達到9萬個,衍生模型數超越Meta的Llama系列,成為了全球第一大開源模型系列。
7日當天,Meta(Nasdaq:META)股價漲2.28%,收於每股516.25美元,總市值1.31萬億美元。
來源:中國澎湃新聞

- 相關推荐
-
-
 藍色起源公佈新發射台方案,讓新格倫火箭再戰蒼穹链接阅读
藍色起源公佈新發射台方案,讓新格倫火箭再戰蒼穹链接阅读 -
 蘋果籌備全新iPad Pro與重新設計的入門級MacBook Pro計畫明年上半年推出基礎版M7晶片链接阅读
蘋果籌備全新iPad Pro與重新設計的入門級MacBook Pro計畫明年上半年推出基礎版M7晶片链接阅读 -
鎢礦資源管理收緊,兩家礦業巨頭合作二十餘年的白鎢回收公司“斷糧”停產链接阅读
-
 歐盟對廉價電商包裹徵收3歐元費用,對Shein、Temu和AliExpress構成打擊链接阅读
歐盟對廉價電商包裹徵收3歐元費用,對Shein、Temu和AliExpress構成打擊链接阅读 -
 英美煙草公司裁員9000人以削減成本链接阅读
英美煙草公司裁員9000人以削減成本链接阅读 -
歷時9個月贛鋒鋰電20億增資終落地,引入戰投未見產業資本身影链接阅读
-
四方達:擬募資20億元佈局金剛石鑽針產業化,適配高階PCB等需求链接阅读
-
Token燒錢太快預算告急,美科技公司陷入AI帳單焦慮链接阅读
-