您當前的位置 :
您當前的位置 : 





國產大模型風向標DeepSeek再發重磅新模型:重點強化智能體能力,並且融入思考和推理過程。
12月1日,DeepSeek同時發佈兩個正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale,官方網頁端、App和API均已更新為正式版 DeepSeek-V3.2,Speciale版本目前僅以臨時API服務形式開放,以供社區評測與研究。
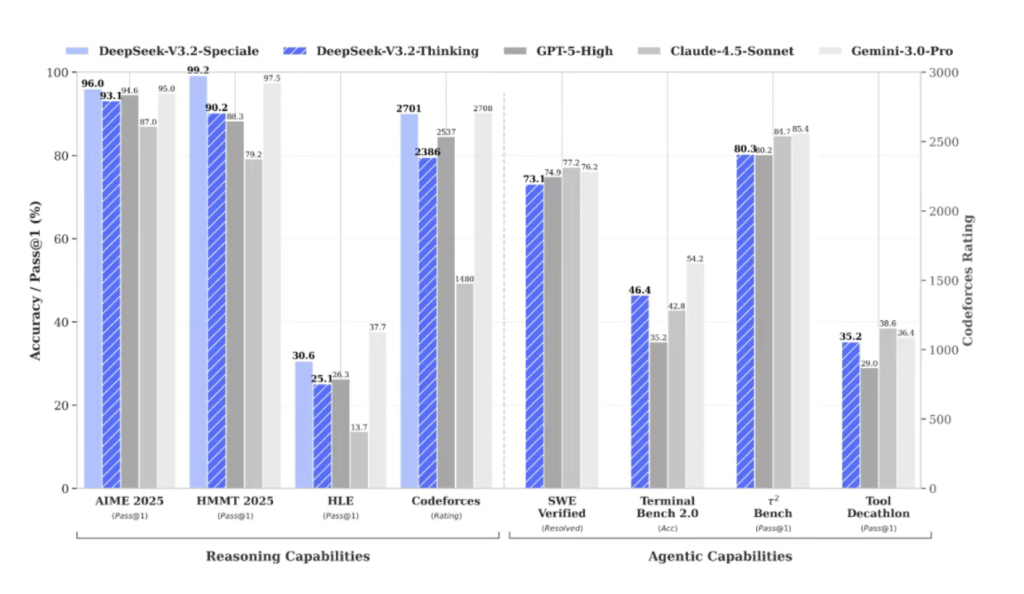
據介紹,DeepSeek-V3.2的目標是平衡推理能力與輸出長度,適合日常使用,例如問答場景和通用Agent(智能體)任務場景。在公開的推理類Benchmark測試中,DeepSeek-V3.2達到GPT-5的水準,僅略低於Gemini-3.0-Pro;相比Kimi-K2-Thinking,V3.2的輸出長度大幅降低,顯著減少計算開銷與用戶等待時間。
據DeepSeek方面介紹,DeepSeek-V3.2-Speciale 的目標是將開源模型的推理能力推向極致,V3.2-Speciale是DeepSeek-V3.2長思考增強版,同時結合DeepSeek-Math-V2定理證明能力。
DeepSeek-V3.2具備指令跟隨、數學證明與邏輯驗證能力,在主流推理基準測試上的性能表現媲美Gemini-3.0-Pro。
不同於過往版本在思考模式下無法調用工具的局限,DeepSeek-V3.2是首個將思考融入工具使用的模型。同時支持思考模式與非思考模式的工具調用,目前提出一種大規模Agent訓練數據合成方法,DeepSeek-V3.2 模型在智能體評測中達到當前開源模型的最高水準,大幅縮小開源模型與閉源模型的差距。
值得說明的是,V3.2並沒有針對這些測試集的工具進行特殊訓練,所以V3.2在真實應用場景中能夠展現出較強的泛化性。
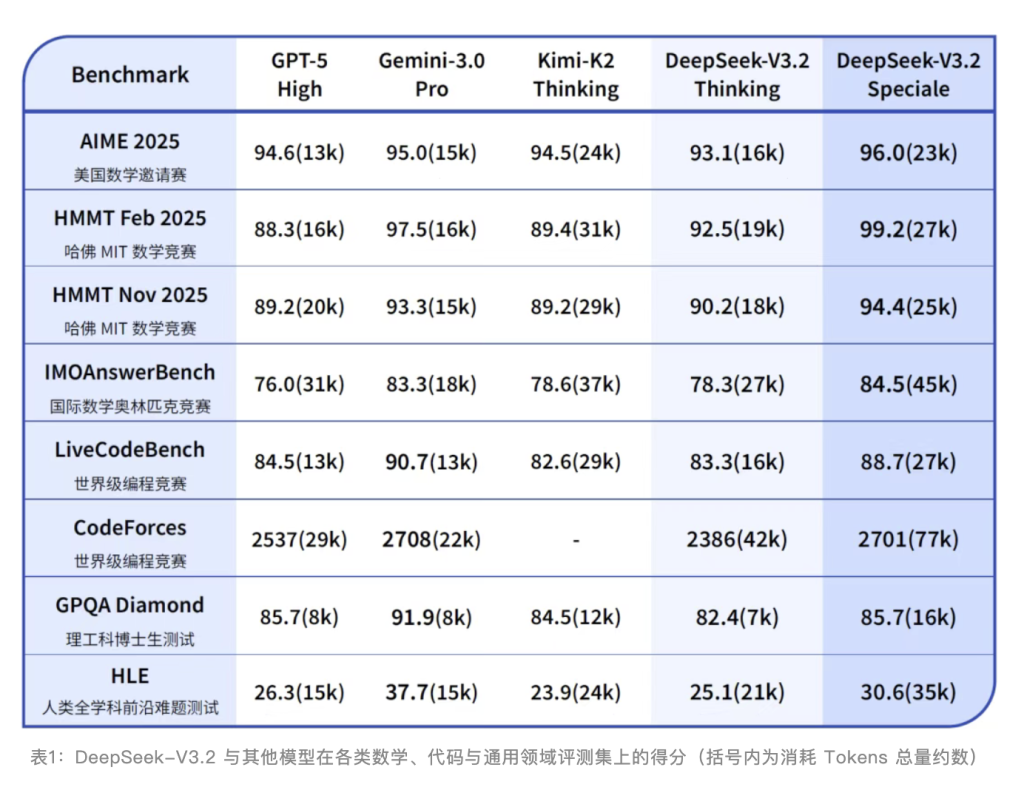
在評測和成績方面,DeepSeek-V3.2-Speciale模型獲得IMO 2025(國際數學奧林匹克)、CMO 2025(中國數學奧林匹克)、ICPC World Finals 2025(國際大學生程式設計競賽全球總決賽)及IOI 2025(國際資訊學奧林匹克)金牌。其中,ICPC與IOI成績分別達到人類選手第二名與第十名的水準。
值得注意的是,DeepSeek指出,在高度複雜任務上,Speciale模型大幅優於標準版本,但消耗的Tokens也顯著更多,成本更高。目前,DeepSeek-V3.2-Speciale僅供研究使用,不支持工具調用,暫未針對日常對話與寫作任務進行專項優化。
DeepSeek是當之無愧的大模型風向標,一舉一動都受到行業整體關注。最近網易有道詞典發佈2025年度辭彙——“deepseek”以 8672940次年度搜索量成功當選。據有道詞典負責人介紹,“deepseek”在詞典內部的搜索曲線呈現明顯的爆發式特徵,從年初因“低成本”突破算力封鎖起,幾乎每個重要進展都會帶動搜索量上漲。
來源:中國澎湃新聞