


 您當前的位置 :
您當前的位置 : 





DeepSeek-V3.1已更新至DeepSeek-V3.1-Terminus版本。
9月22日晚間,據DeepSeek介紹,此次更新在保持模型原有能力的基礎上,針對用戶回饋的問題進行了改進,包括:語言一致性:緩解中英文混雜、偶發異常字元等情況。在Agent(智能體)能力方面,進一步優化Code Agent與Search Agent的表現,DeepSeek-V3.1-Terminus的輸出效果相比前一版本更加穩定。
目前,官方App、網頁端、小程式與DeepSeek API模型均已同步更新為DeepSeek-V3.1-Terminus。不過,記者看到這款大模型名為Terminus,意思是“終極版”,或許這也是V3.1最後一次更新。外界觀望下一次大版本更新到底是V4還是R2的到來。
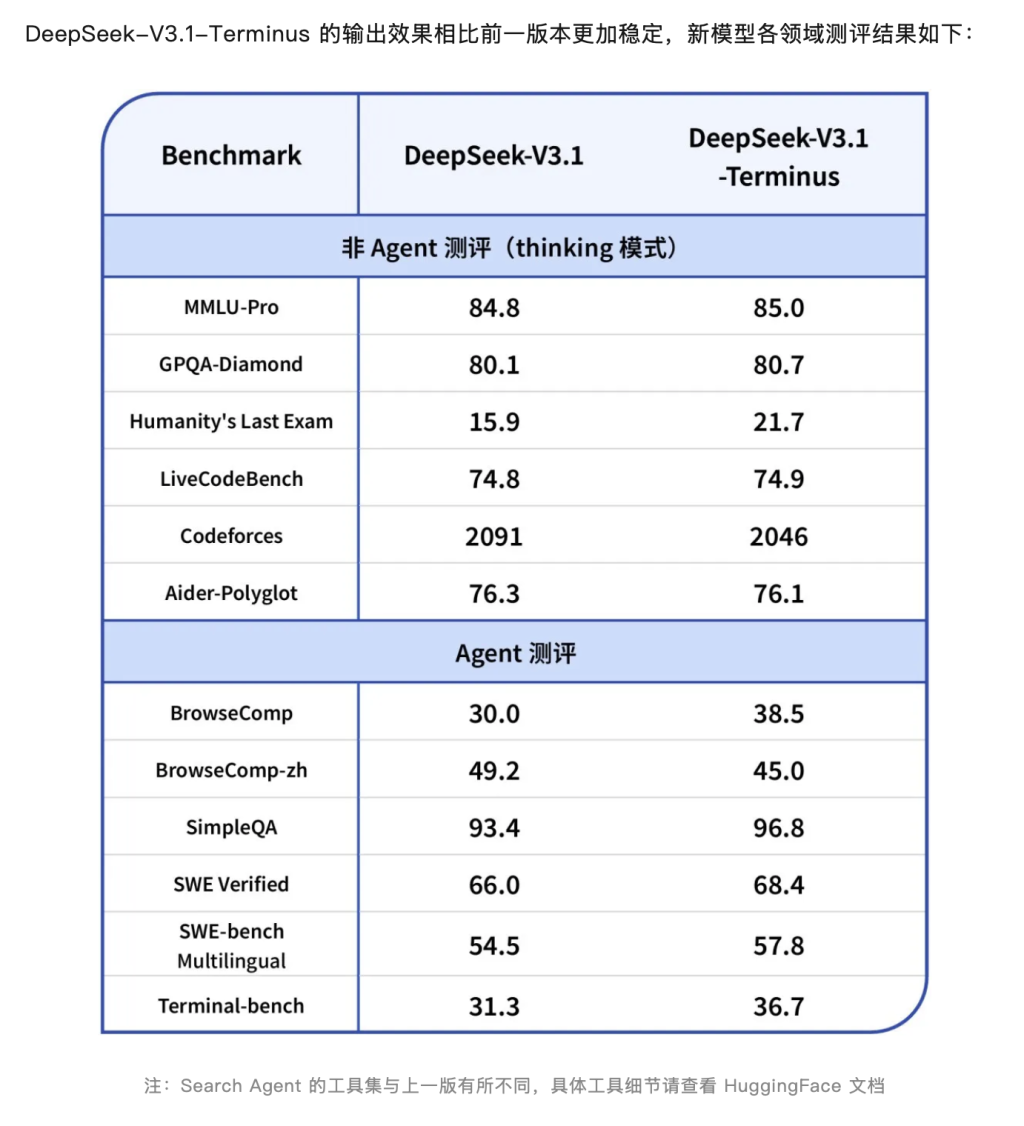
在公開的基準測試成績中,V3.1-Terminus整體較V3.1有所提升,不過其中部分分數也有下滑,不過在“人類最後考試”(Humanity’s Last Exam)基準上進步較為突出,分數從 15.9大幅提升至21.7,根據官網數據,這一成績僅次於 Grok 4(25.4)和GPT-5(25.3),並略微超越 Gemini 2.5 Pro(21.6)。
值得注意的是,DeepSeek在中英文混雜方面的改進尤為受到歡迎。澎湃新聞記者在社交媒體上看到,不少用戶點贊:“中英文混雜問題在思考時間很長的時候確實會出現,遇到過幾次,還在想這是什麼問題,這下子正好給解決了。”
資深AI投資人郭濤向記者分析稱,本次DeepSeek-V3.1-Terminus版本更新聚焦工程化落地與場景適配,核心突破體現在兩大核心競爭提升:一方面,通過語義層降噪技術顯著改善語言一致性,有效抑制中英文混雜、異常字元等干擾,提升文本生成純淨度;另一方面,深度重構Agent執行框架,針對Code Agent的語法解析精度、Search Agent的資訊檢索召回率進行專項優化,使智能體輸出穩定性提升。
此次全管道(App/網頁/小程式/API)同步升級,展現國產大模型從演算法創新向工程可靠性演進的關鍵跨越,標誌著國產模型在複雜任務處理、多模態協同等工業化應用層面邁出重要一步,為後續垂直領域深度賦能奠定更堅實基礎。
作為國產大模型的風向標,DeepSeek的動態都廣泛被外界關注。
此前9月18日,梁文鋒帶著DeepSeek-R1的研究,登上最新一期國際頂級期刊《自然》(Nature)封面。
今年1月份,國產大模型公司深度求索(DeepSeek)在預印本平臺arxiv公佈論文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,創始人梁文鋒位於署名之列。
《自然》雜誌指出,如此總結DeepSeek-R1帶來的進步:如果訓練出的大模型能夠規劃解決問題所需的步驟,那麼它們往往能夠更好地解決問題。這種“推理”與人類處理更複雜問題的方式類似,但這對人工智慧有極大挑戰,需要人工干預來添加標籤和注釋。
DeepSeek的研究人員揭示了他們如何能夠在極少的人工輸入下訓練一個模型,並使其進行推理。DeepSeek-R1模型採用強化學習進行訓練。在這種學習中,模型正確解答數學問題時會獲得高分獎勵,答錯則會受到懲罰。
DeepSeek團隊也首次對外回應“蒸餾”相關質疑。論文中表示,對於深度求索V3基礎版(DeepSeek-V3-Base)的訓練數據僅使用普通網頁和電子書,未納入任何合成數據,“不過,我們注意到部分網頁包含大量由OpenAI模型生成的答案,這可能會讓基礎模型間接地從其他強大模型獲取知識。但在預訓練冷卻階段,我們並未刻意加入由OpenAI生成的合成數據;該階段使用的所有數據都是通過網路爬取自然獲取的。預訓練數據集包含大量與數學和代碼相關的內容,這表明深度求索V3基礎版接觸到大量的推理軌跡數據。”
今年1月20日,中國AI初創公司深度求索(DeepSeek)推出大模型DeepSeek-R1引爆AI行業,作為一款開源模型,R1在數學、代碼、自然語言推理等任務上的性能能夠比肩OpenAIo1模型正式版,並採用MIT許可協議,支持免費商用、任意修改和衍生開發等。春節假期後,國內多個行業龍頭公司均宣佈接入DeepSeek。
伴隨AI大模型行業的日新月異,DeepSeek已經更新出R1以外的新版本,但萬眾期待的R2尚未面世。此前8月21日DeepSeek正式發佈DeepSeek-V3.1,稱其為“邁向Agent(智能體)時代的第一步”。
來源:中國澎湃新聞






