








 您當前的位置 :
您當前的位置 :
全球首個統一多模態視頻模型,快手可靈視頻O1模型全量上線
发布:2025-12-02






12 月 1 日消息,可靈 AI 今晚通過官方公眾號宣佈,全球首個統一多模態視頻模型 —— 可靈視頻 O1 模型全量上線。
記者從官方介紹獲悉,可靈 O1 模型構建了全新生成式底座,從而能夠“打破功能割裂”,並引入 MVL(多模態視覺語言)交互架構,可在單一輸入框內無縫融合多種任務。結合 Chain-of-thought 技術,模型從而具備強大的常識推理與事件推演能力。
官方更稱,依託統一模型的深層語義理解力,“每一張照片、每一個視頻、每一段文字,在可靈 O1 眼中皆是指令”。同時上線的還有全新創作界面,僅需簡單對話,輕鬆使用各種素材,精准生成每一處細節。
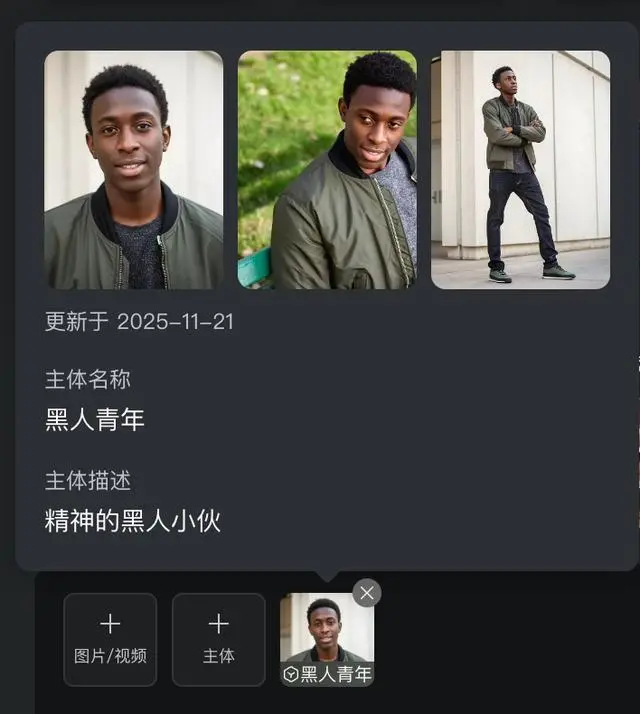
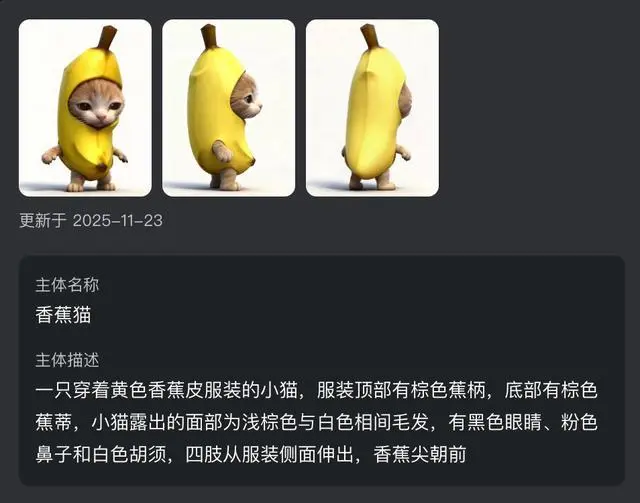
其支持多視角構建主體,號稱無論鏡頭如何流轉,主體特徵都能穩定如一,確保畫面精准、連貫。同時,其支持自由組合多個主體。

來源:中國IT之家







